What are Flows?
Flows are visual representations of your RAG pipelines that define how documents are processed, chunked, indexed, and queried. Each flow consists of interconnected nodes that perform specific functions in your data processing pipeline.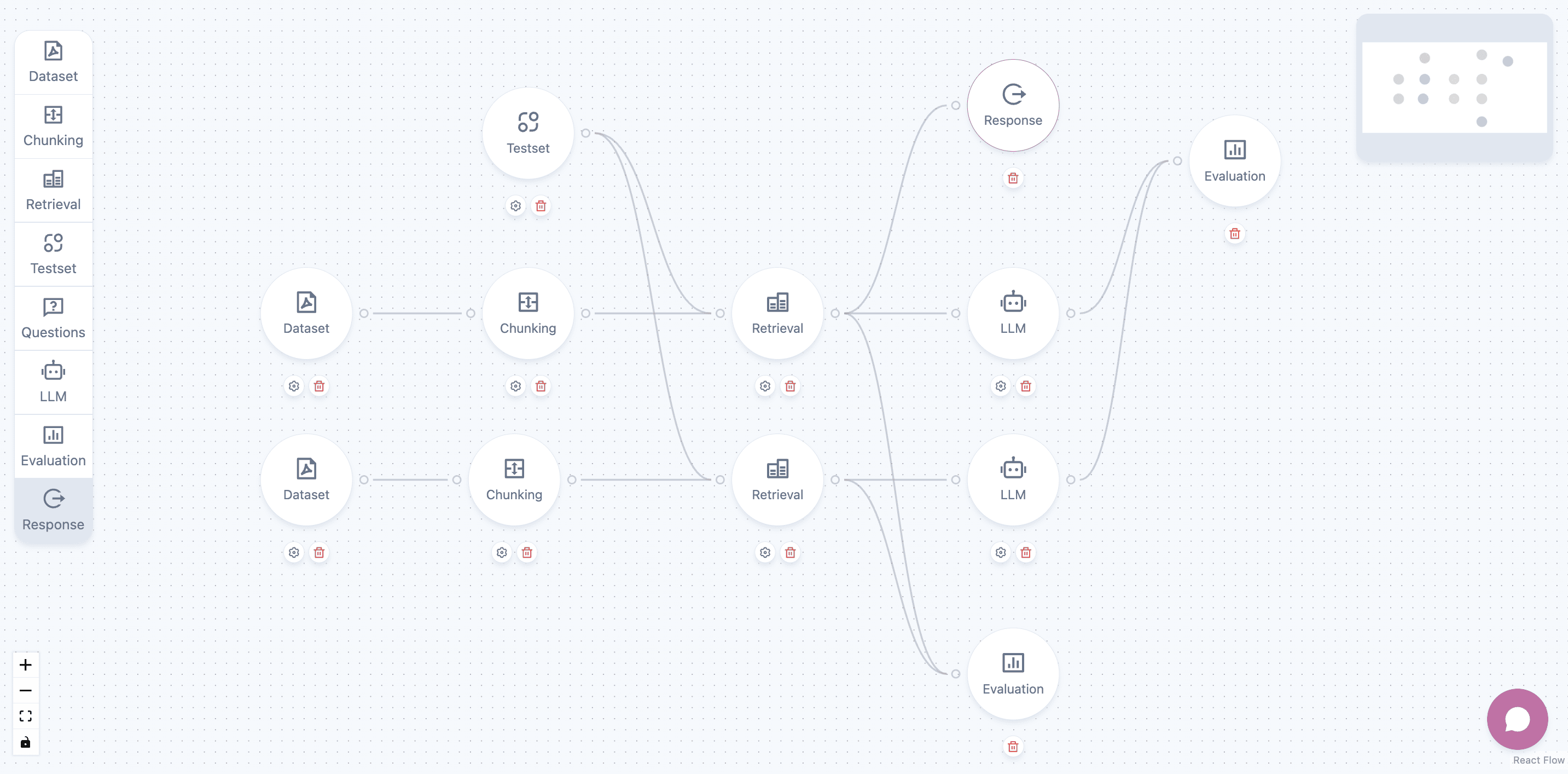
Core Flow Components
- Dataset Nodes: Connect source documents to your pipeline
- Chunking Nodes: Split documents into smaller text chunks with embeddings
- Retrieval Nodes: Perform similarity search and document retrieval
- Reranking Nodes: Use LLMs to reorder retrieved documents by relevance
- Smart RAG Nodes: Intelligent RAG with combined chunking and retrieval
- Graph RAG Nodes: Advanced RAG with knowledge graph construction
- RAPTOR RAG Nodes: Hierarchical RAG with tree-based document clustering
- LLM Nodes: Generate natural language responses with quality evaluation
Available API Endpoints
The Flows API is organized into several categories for comprehensive flow and node management:Flow Management
Core endpoints for managing flow lifecycles:List Flows
Retrieve all flows in your project with status and deployment information
Run Flow
Execute deployed flows with queries and receive processed results
Deploy Flow
Deploy flows to make them accessible via the public API
Dataset Nodes
Manage source document connections:Dataset Overview
Comprehensive guide to dataset node management
List Dataset Nodes
Retrieve dataset nodes from flows with configurations
Update Dataset
Modify dataset node configurations and file selections
Processing Nodes
Handle document processing and retrieval:Chunking Nodes
Split documents into chunks with embedding generation
Retrieval Nodes
Perform similarity search and document retrieval operations
Reranking Nodes
Use LLMs to reorder documents by relevance scores
Advanced RAG Nodes
Sophisticated RAG implementations:Smart RAG
Intelligent RAG with combined chunking and retrieval
Graph RAG
Advanced RAG with knowledge graph construction
RAPTOR RAG
Hierarchical RAG with tree-based document clustering
LLM Nodes
Response generation and prompt management:LLM Overview
Comprehensive guide to LLM node management and optimization
List LLM Nodes
Retrieve LLM nodes with configurations and performance metrics
Update LLM Configuration
Modify LLM settings including model selection and parameters
List Prompts
Access available prompt templates for LLM customization
Authentication
All Flows API endpoints require authentication using API tokens:Learn how to generate and manage API tokens in the API Tokens guide.
URL Structure
Flow endpoints follow consistent URL patterns based on their purpose:Global Flow Operations
Flow-Specific Operations
Common Workflow Patterns
Complete Flow Lifecycle
Here’s a typical workflow for managing flows from creation to execution:1. Flow Creation and Configuration
2. Flow Deployment
3. Flow Execution
Response Formats
Flow Object Structure
Dataset Node Structure
Execution Results
Error Handling
The Flows API uses standard HTTP status codes and provides detailed error messages:| Status Code | Description | Common Causes |
|---|---|---|
| 400 | Bad Request | Invalid parameters, malformed JSON |
| 401 | Unauthorized | Invalid or missing API token |
| 404 | Not Found | Flow doesn’t exist, node not found |
| 500 | Internal Server Error | Processing errors, system issues |
Error Response Format
Integration Examples
Flow Management Client
Python Integration
Best Practices
Flow Development Lifecycle
-
Planning Phase
- Design your flow architecture in the Graphor UI
- Identify required datasets and processing steps
- Plan your API integration strategy
-
Configuration Phase
- Use the API to configure dataset nodes programmatically
- Validate file availability before deployment
- Test configurations with small datasets first
-
Deployment Phase
- Deploy flows with descriptive tool descriptions
- Monitor deployment status and handle errors
- Verify deployment success before proceeding
-
Execution Phase
- Start with simple queries to test functionality
- Implement proper error handling and retry logic
- Monitor performance and optimize as needed
Performance Optimization
- Batch Operations: Update multiple dataset nodes in parallel
- Caching: Cache flow metadata and configurations
- Pagination: Use appropriate page sizes for large result sets
- Connection Pooling: Reuse HTTP connections for multiple requests
Error Prevention
- Validation: Always validate inputs before API calls
- Status Checking: Monitor flow and dataset status regularly
- Graceful Degradation: Handle API failures gracefully
- Logging: Implement comprehensive logging for debugging
Security Best Practices
- Token Management: Securely store and rotate API tokens
- Environment Separation: Use different tokens for dev/staging/prod
- Input Sanitization: Validate all user inputs before processing
- Rate Limiting: Implement client-side rate limiting
Monitoring and Troubleshooting
Health Monitoring
Common Issues and Solutions
Flow Not Found
Flow Not Found
Causes: Incorrect flow name, missing permissions, flow not createdSolutions:
- Verify flow name spelling and case sensitivity
- Check API token permissions
- Ensure flow exists in the correct project
Deployment Failures
Deployment Failures
Causes: Invalid configuration, missing files, processing errorsSolutions:
- Validate all dataset configurations before deployment
- Check that all referenced files exist and are processed
- Review flow configuration for errors
Execution Timeouts
Execution Timeouts
Causes: Complex queries, large datasets, resource constraintsSolutions:
- Simplify queries or break them into smaller parts
- Optimize dataset configurations
- Contact support for resource scaling
Dataset Configuration Issues
Dataset Configuration Issues
Causes: Missing files, outdated nodes, invalid file referencesSolutions:
- Use the List Sources endpoint to verify file availability
- Update dataset nodes with valid file lists
- Redeploy flows after configuration changes
Advanced Use Cases
Multi-Environment Deployment
Automated Testing Pipeline
Next Steps
Ready to start building with the Flows API? Here’s your roadmap:Getting Started
List Flows
Start by exploring your existing flows and their status
Deploy Flow
Learn how to deploy your flows for public access
Node Management
Processing Nodes
Master chunking, retrieval, and reranking node configurations
Advanced RAG
Explore Smart RAG, Graph RAG, and RAPTOR RAG capabilities
LLM Integration
Configure LLM nodes for response generation and optimization
Flow Execution
Execute your deployed flows and process queries
Integration Guides
Data Ingestion
Learn about uploading and processing source documents
Integrate Workflow
Advanced patterns for production integrations
API Tokens
Generate and manage authentication tokens
Evaluation
Test and optimize your RAG pipeline performance