Overview
Graphor’s data ingestion process involves:- Document upload - Import files from various sources
- Text extraction - Convert documents to machine-readable text
- Structure recognition - Identify document elements and hierarchy
- Metadata extraction - Capture important document properties
- Content classification - Categorize document sections
Supported Document Types
Graphor supports a wide range of document formats:| Document Type | Extensions | Features |
|---|---|---|
| Text Documents | PDF, TXT, TEXT, MD, DOC, DOCX, HTML, HTM | Full text extraction, structure preservation |
| Images | PNG, JPG, JPEG, TIFF, BMP, HEIC | OCR for text extraction, image analysis |
| Presentations | PPT, PPTX | Slide extraction, image processing |
| Spreadsheets | XLS, XLSX, CSV, TSV | Table parsing, data extraction |
| Audio Files | MP3, WAV, M4A, OGG, FLAC | Speech-to-text transcription, audio analysis |
| Video Files | MP4, MOV, AVI, MKV, WEBM | Video transcription, visual content extraction |
| Web Content | URL | Web scraping, content extraction |
| Code Repositories | GitHub URL | Repository content extraction, code analysis |
| Video Content | YouTube URL | Video transcription, content extraction |
Importing Documents
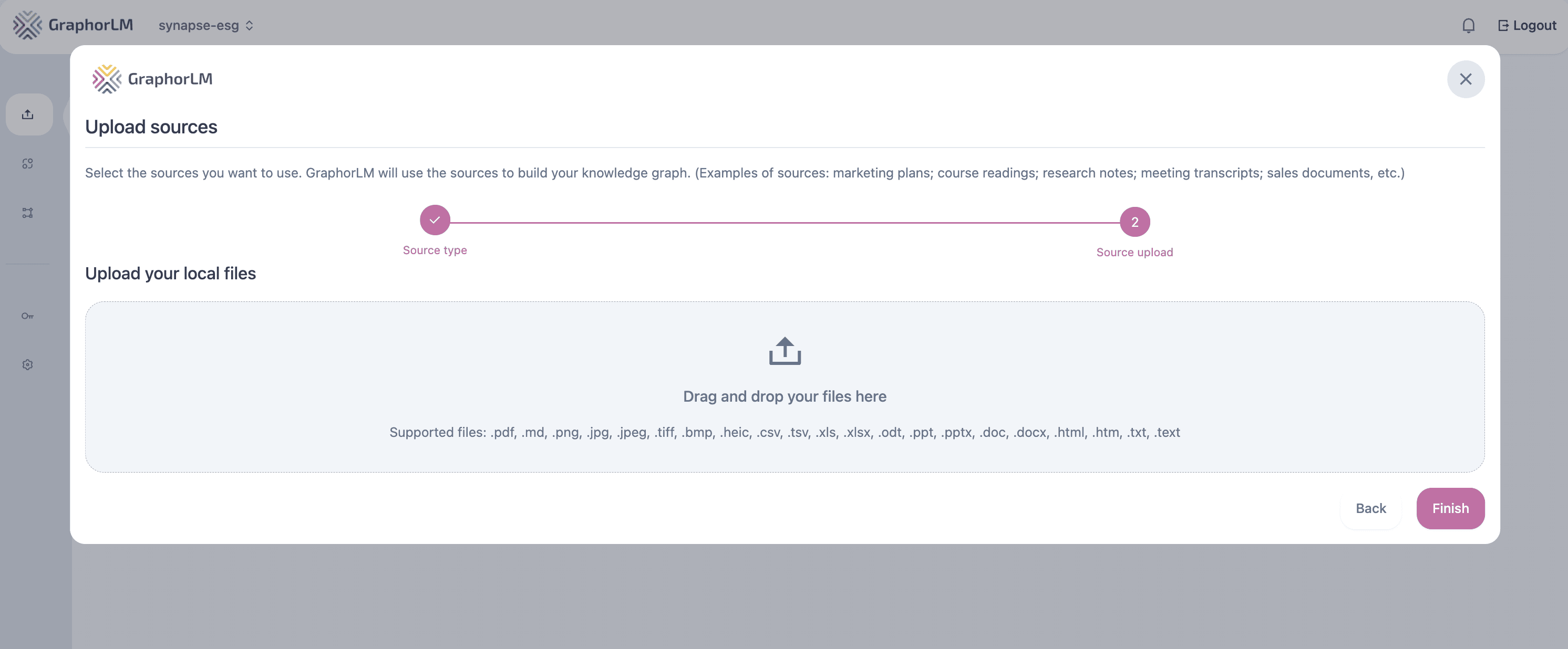
There are several ways to import documents into Graphor:Method 1: Local Files Upload
You have two options for uploading local files: Option 1: Drag and drop directly- Simply drag and drop your files anywhere on the Sources page
- Navigate to Sources in the left sidebar
- Click Add
- Select Local files
- Select your files or drag and drop them into the upload area
- Click Finish to begin processing
Method 2: URL Import
To import content directly from a web address:- Navigate to Sources in the left sidebar
- Click Add
- Select Web page
- Enter the web address of the content you want to import
- Optionally enable Crawl URLs to extract links and import related pages
- Click Finish to begin processing
Method 3: GitHub Repository Import
To import content from a GitHub repository:- Navigate to Sources in the left sidebar
- Click Add
- Select GitHub
- Enter the GitHub repository URL (e.g.,
https://github.com/username/repository) - Click Finish to begin processing
- Code documentation and analysis
- Repository knowledge bases
- Technical documentation extraction
- Open source project analysis
Method 4: YouTube Video Import
To import content from YouTube videos:- Navigate to Sources in the left sidebar
- Click Add
- Select YouTube
- Enter the YouTube video URL
- Click Finish to begin processing
- Lecture and educational content extraction
- Meeting and conference transcription
- Video-based knowledge extraction
- Audio content analysis
Advanced OCR Processing
Graphor utilizes state-of-the-art OCR (Optical Character Recognition) to extract text from images and scanned documents.OCR Features
- Multi-language support - Recognize text in various languages
- Layout preservation - Maintain document structure and formatting
- Table detection - Extract structured data from tables
- Image text extraction - Identify and capture text embedded in images
- Handwriting recognition - Process handwritten notes (with varying accuracy)
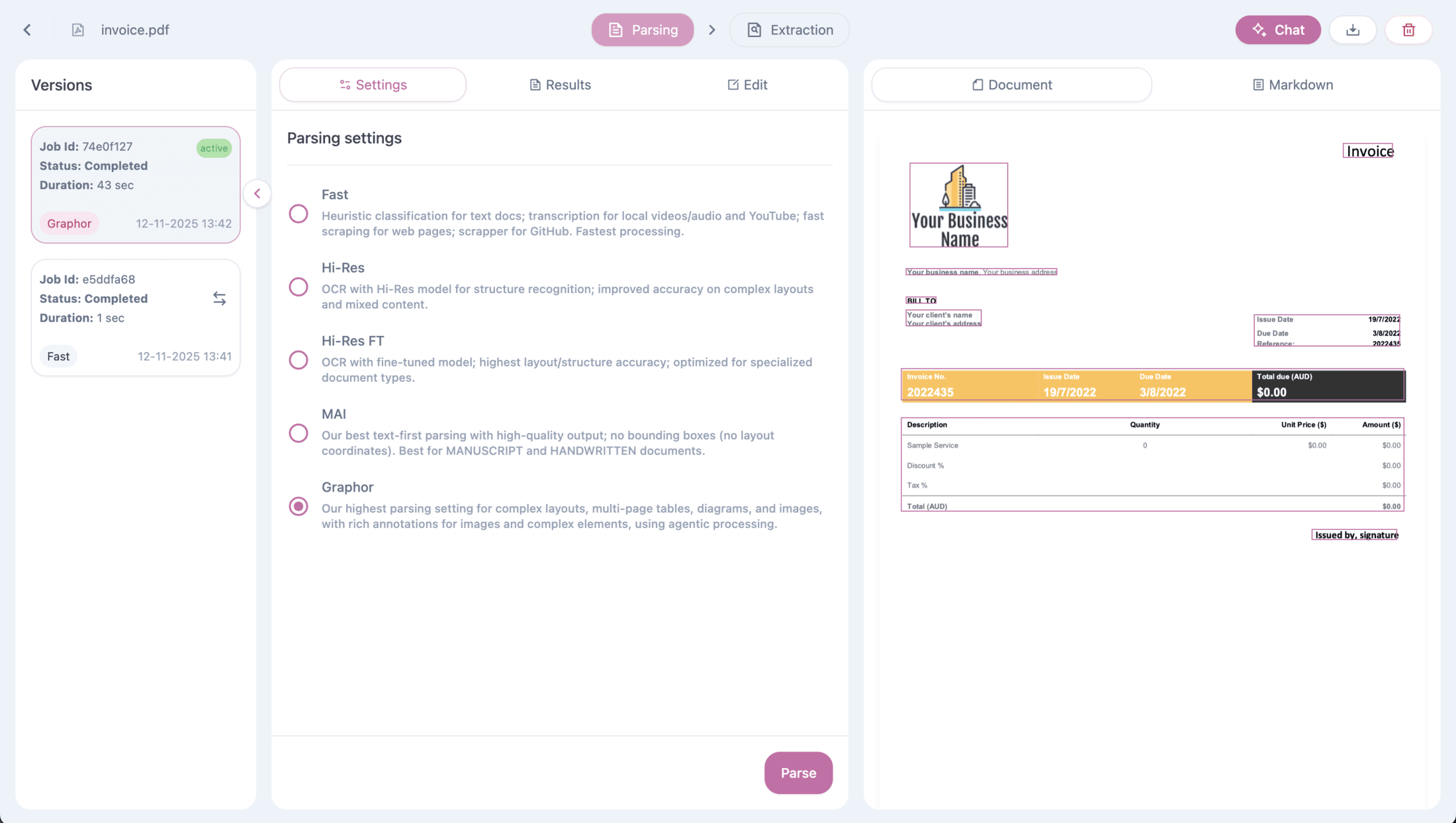
Document Parsing Methods
When you upload a source, Graphor automatically applies the Fast parsing method. For more complex documents, you can manually apply advanced parsing methods. Graphor offers five parsing methods to optimize document processing based on your needs:Auto
- Per-page routing — classifies each page and runs the cheapest parser that fits
- Body pages run on Fast, table pages on Accurate, scanned/image pages on Agentic — automatically
- Billed per page on the effective method used, not a flat per-document price
- Best balance of cost and quality on mixed PDFs (covers + body + tables + scans in one document)
- PDF-only today. Non-PDF sources fall back to Fast.
Fast
- Heuristic classification for text documents
- Transcription for local videos/audio and YouTube
- Fast scraping for web pages
- Scraper for GitHub repositories
- Fastest processing option (applied by default)
Balanced
- OCR with Hi-Res model for structure recognition
- Improved accuracy on complex layouts and mixed content
- Better recognition of document structure and components
Accurate
- OCR with fine-tuned model
- Highest layout/structure accuracy
- Optimized for specialized document types
Agentic
- Our highest parsing setting for complex layouts
- Multi-page tables, diagrams, and images support
- Rich annotations for images and complex elements
- Uses agentic processing for enhanced understanding
Selecting a Parsing Method
To apply a different parsing method:- Click on a processed file from the Sources list to access Source details
- Navigate to the Settings tab
- Select your preferred parsing method
- Click Parse to apply the new method
- Wait for processing to complete
Processing Time Estimates
Processing time varies based on the parsing method and document complexity:| Method | Typical Processing Time | Best For |
|---|---|---|
| Auto | Mixed (per page) | Mixed PDFs with body + tables + scans |
| Fast | Seconds | Simple text documents, quick iteration |
| Balanced | 10-30 seconds per page | Complex layouts requiring OCR |
| Accurate | 15-45 seconds per page | Specialized documents needing highest accuracy |
| Agentic | 30-60+ seconds per page | Complex multi-page tables, diagrams |
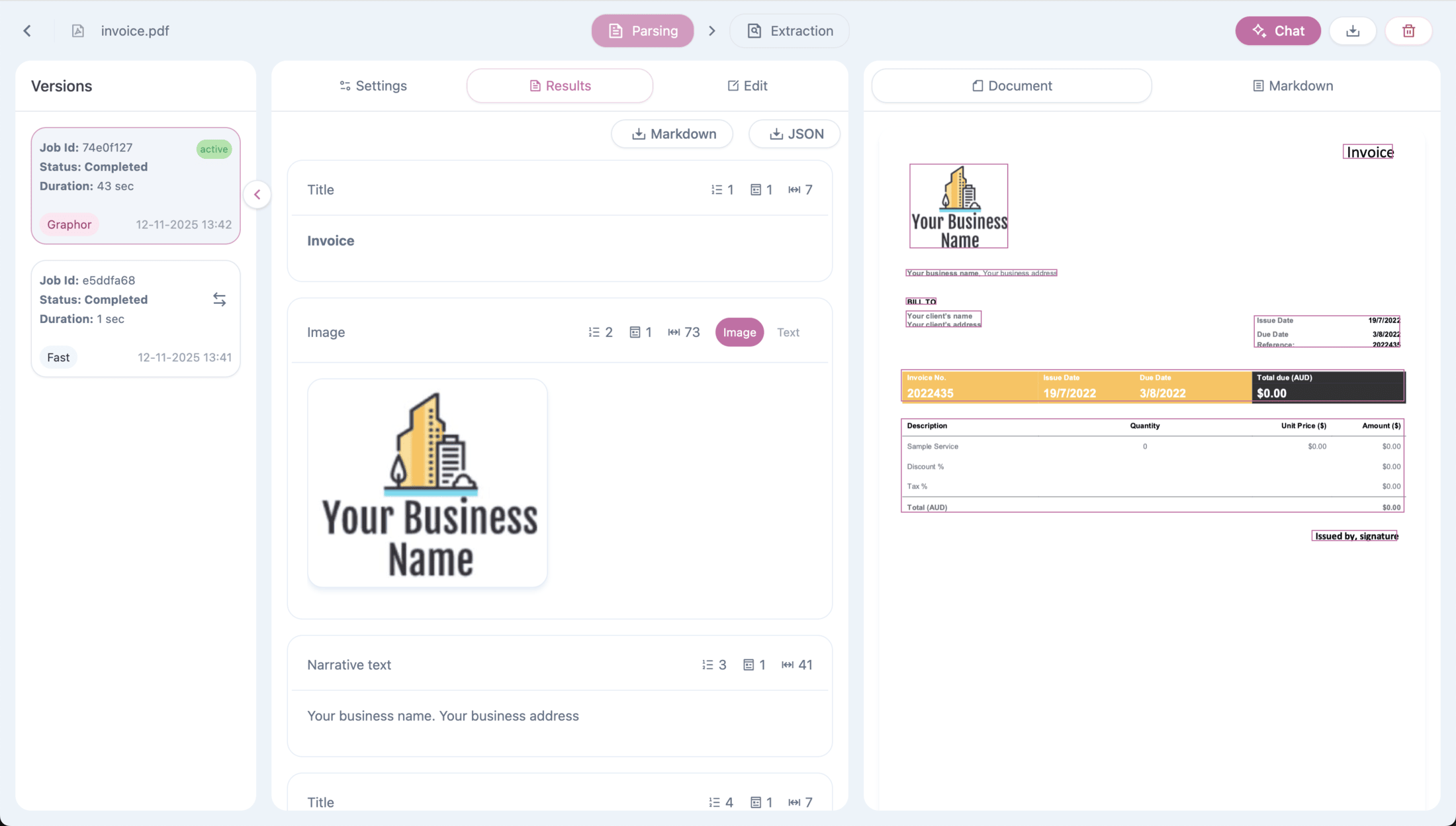
Viewing Parsing Results
After parsing completes, you can review the results in the Results tab:- Document view — Visual representation of the parsed content with element highlighting
- Markdown view — Raw markdown output ready for downstream processing
- Page navigation — Browse through multi-page documents page by page
- Element types — See how each section was classified (Title, Narrative text, Table, etc.)
Editing Parsed Content
The Edit tab allows you to manually refine the parsed output:- Correct OCR errors — Fix text recognition mistakes
- Adjust element types — Change how sections are classified
- Modify structure — Reorganize content hierarchy
- Add annotations — Include custom notes or metadata
Version History
Every parsing result is saved and available in the Versions panel on the left side of the Source details page. Each version displays:- Job ID — Unique identifier for the parsing job
- Status — Completed, Failed, or Processing
- Duration — How long the parsing took
- Parsing method — Which method was used (Fast, Balanced, etc.)
- Timestamp — When the parsing was executed
- Compare different parsing methods — Try multiple methods and compare results side by side
- Switch active version — Click on any version to set it as active
- Automatic activation — When a new parsing completes successfully, it’s automatically set as the active version
- Preserve history — Previous versions are never deleted, allowing you to revert at any time
Content Classification
Graphor can automatically classify document sections to improve retrieval relevance:Document Element Types
The platform classifies content into the following specific element types:- Title - Document and section titles
- Narrative text - Main body paragraphs and content
- List item - Items in bullet points or numbered lists
- Table - Complete data tables
- Table row - Individual rows within tables
- Image - Picture or graphic elements
- Footer - Footer content at bottom of pages
- Formula - Mathematical formulas and equations
- Composite element - Elements containing multiple types
- Figure caption - Text describing images or figures
- Page break - Indicators of page separation
- Address - Physical address information
- Email address - Email contact information
- Page number - Page numbering elements
- Code snippet - Programming code segments
- Header - Header content at top of pages
- Form keys values - Key-value pairs in forms
- Link - Hyperlinks and references
- Uncategorized text - Text that doesn’t fit other categories
Metadata Extraction
Graphor automatically extracts and processes document metadata:- File name and type
- Creation and modification dates
- Document size and page count
- Author information (when available)
- Title and description
Monitoring Processing Status
Monitor the progress of document processing in the Sources dashboard:- Waiting - Documents queued for processing
- Uploading - Documents currently being uploaded
- Processing - Documents currently being parsed
- Processed - Documents successfully parsed and ready for use
- Not parsed - Documents uploaded but not yet parsed (e.g., URLs, YouTube)
- Failed - Documents that encountered errors during processing
Batch Operations
Graphor supports batch operations to help you manage multiple sources efficiently:Uploading Multiple Files
- Drag and drop multiple files at once onto the Sources page
- Select multiple files in the upload interface
- Files are processed in parallel for faster ingestion
Deleting Multiple Sources
To delete multiple sources at once:- Single-click on sources to select them (double-click opens Source details)
- Click the Delete button in the toolbar
- Confirm the deletion
Programmatic Integration
All data ingestion operations can be automated using Graphor’s REST API. The project context is already included in your API token. Base URL:https://sources.graphorlm.com
Upload a File
Upload from URL
Upload from GitHub
Process with Specific Parsing Method
List All Sources
Delete a Source
Best Practices
To optimize data ingestion results:General Practices
- Use consistent formats - When possible, standardize document formats
- Check processing results - Review extracted text for accuracy
- Customize for complex documents - Use advanced parsing for specialized content
- Monitor processing status - Check for failed documents and resolve issues
Source-Specific Practices
For Local Files:- Optimize file sizes before upload (large files are processed in chunks automatically)
- Use descriptive filenames for better organization
- Group related documents for batch processing
- Enable “Crawl URLs” for comprehensive site extraction
- Verify URLs are publicly accessible
- Consider the depth of crawling for large websites
- Use specific branch or tag URLs when needed
- Be aware that large repositories may take longer to process
- Ensure videos have clear audio for better transcription
- Consider video length - longer videos require more processing time
- Check that videos are publicly accessible
- Use high-quality audio for better transcription accuracy
- Consider file size limits and processing time
- Ensure proper audio codecs for compatibility
Processing Method Selection
- Auto: Use for mixed PDFs (body + tables + scans in one document) — routes each page to the cheapest parser that fits. PDF-only.
- Fast: Use for simple text documents and fastest processing (applied by default)
- Balanced: Ideal for complex layouts and mixed content types with OCR
- Accurate: Best for specialized document types requiring highest layout accuracy
- Agentic: Use for complex layouts, multi-page tables, diagrams, and images requiring rich annotations
Troubleshooting
Common issues and solutions:Poor OCR quality
Poor OCR quality
For low-quality scanned documents, try:
- Using Balanced, Accurate, or Agentic methods instead of Fast
- Breaking large documents into smaller files
- Improving document quality before upload if possible
Table extraction problems
Table extraction problems
If tables aren’t being properly recognized:
- Use Balanced, Accurate, or Agentic method for better table detection
- Agentic is best for multi-page tables
- Convert complex tables to simpler formats before upload
Multi-language document issues
Multi-language document issues
For documents with multiple languages:
- Process different language sections as separate documents
- Use Balanced, Accurate, or Agentic method which has better multi-language support
Slow processing time
Slow processing time
If processing is taking too long:
- Use Fast method for simple documents
- Avoid Accurate or Agentic unless you need their advanced features
GitHub repository access issues
GitHub repository access issues
If you’re having trouble importing from GitHub:
- Ensure the repository is public or you have proper access permissions
- Check that the repository URL is correctly formatted
- Large repositories may take longer to process - be patient during import
YouTube video processing issues
YouTube video processing issues
For YouTube video import problems:
- Verify the video URL is accessible and not private
- Note that very long videos may take significant processing time
- Audio quality affects transcription accuracy
Audio/Video processing issues
Audio/Video processing issues
For audio and video file problems:
- Ensure audio quality is clear for better transcription results
- Large video files may be automatically processed in chunks
- Check that audio language is supported for transcription
Next Steps
After successfully ingesting your documents, explore these next steps:Data Extraction
Extract structured data from your documents using custom schemas and natural language instructions
Document Chat
Ask questions and get answers grounded in your document content
API Tokens
Set up authentication for programmatic access to your documents and data
API Reference
Integrate document upload into your applications using the REST API