Overview
Effective document chunking is critical for RAG pipeline performance. This guide explains:- What chunking is and why it matters
- Graphor’s chunking strategies and capabilities
- How to configure chunking for your specific use case
- Best practices for optimizing retrieval quality
What is Chunking?
Chunking is the process of breaking down documents into smaller, manageable segments (chunks) that can be:- Embedded effectively as vectors
- Retrieved efficiently during the search process
- Processed meaningfully by language models
- Retrieval accuracy: How well the system finds relevant information
- Context quality: How complete and coherent the retrieved information is
- Processing efficiency: How quickly the system can handle and respond to queries
Element-Aware Chunking in Graphor
Graphor leverages document structure and element classifications (from the data ingestion phase) to make intelligent chunking decisions:- Preserves semantic units: Keeps related content together
- Respects document hierarchies: Maintains the relationship between headings and content
- Handles special elements: Properly processes tables, lists, and code blocks
Available Chunking Strategies
Graphor provides multiple chunking strategies, each with specific use cases and configuration requirements:Smart Chunking
- How it works: Uses document structure and element classification to make intelligent splitting decisions
- Configuration required:
- Chunk Size: Maximum size of each chunk (actual chunks are typically smaller based on content boundaries)
- Best for: Complex documents with varied structures, headings, and special elements
- Advantages: Preserves meaning, maintains context, respects document hierarchy
- Limitations: May produce variable chunk sizes
By Character
- How it works: Splits text based on a fixed number of characters
- Configuration required:
- Chunk Size: Maximum number of characters per chunk (actual chunks may be smaller when using separators)
- Overlap: Number of characters to overlap between chunks
- Separator (optional): Character or string to use as chunk boundary
- Best for: Simple, uniform documents with straightforward content
- Advantages: Fast processing, consistent chunk sizes
- Limitations: May break semantic units and natural document flow
By Element
- How it works: Creates chunks based on document element types from the classification process
- Configuration required: None (automatically uses element boundaries)
- Best for: Documents with well-defined structural elements
- Advantages: Preserves natural document elements (paragraphs, sections, tables)
- Limitations: Chunk sizes can vary dramatically based on element length
By Tokens
- How it works: Creates chunks with a specific token count limit
- Configuration required:
- Chunk Size: Maximum number of tokens per chunk (actual chunks will often be smaller due to sentence or paragraph boundaries)
- Overlap: Number of tokens to overlap between chunks
- Best for: Optimizing for LLM context window sizes
- Advantages: Precise control over token usage, better for managing resource efficiency
- Limitations: May not respect semantic boundaries
By Semantic
- How it works: Uses semantic analysis to identify natural conceptual boundaries in text
- Configuration required: None (automatically determines semantic boundaries)
- Best for: Documents where semantic meaning spans across structural elements
- Advantages: Creates more meaningful chunks based on content rather than just structure
- Limitations: More computationally intensive, may produce less predictable chunks
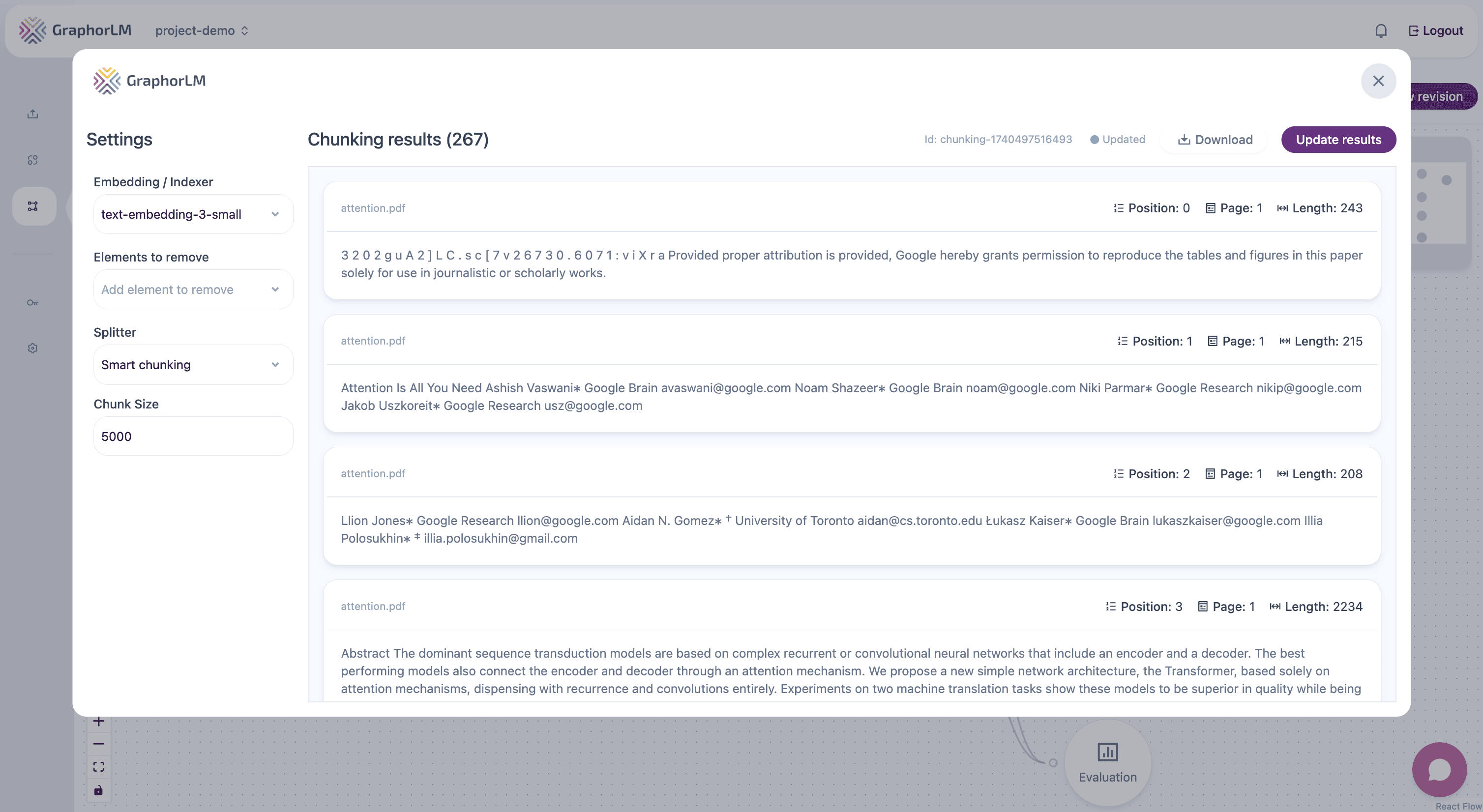
Using the Chunking Component
In the Flow Builder, the Chunking component processes your documents for optimal retrieval: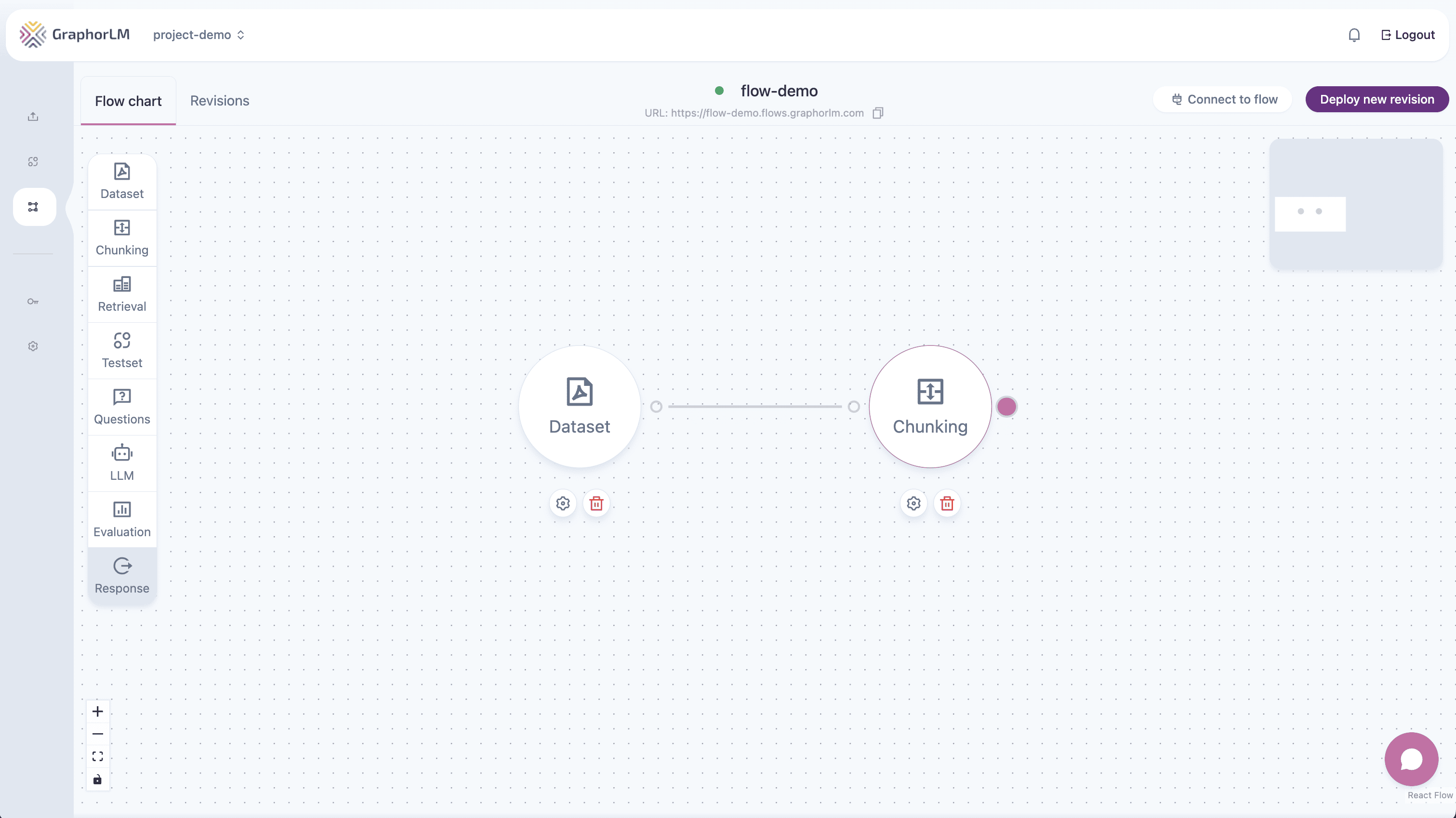
Step-by-Step Configuration
- Add the Chunking component to your flow
- Connect your Dataset component to the Chunking component’s input
- Double-click the Chunking component to open its configuration panel
- Configure the following settings:
1. Embedding / Indexer
Select the embedding model to use for converting text chunks into vector representations:- text-embedding-3-small: OpenAI’s efficient embedding model (recommended for most use cases)
- text-embedding-3-large: OpenAI’s larger, more precise embedding model
- text-embedding-ada-002: Legacy OpenAI embedding model
- colqwen2-v0.1 (vision): Uses Colpali technology to generate embeddings from images rather than text
- Only compatible with PDF documents and images (PNG, JPG, etc.)
- Documents in other formats will be ignored during chunking when this option is selected
- Creates multimodal chunks that leverage both visual and textual information
- Particularly effective for documents where visual elements are important to understanding
- Performance note: Using Colpali technology can impact both simulation and runtime performance of your RAG pipeline
- Requires more computational resources and may increase processing time
- May result in slower response times during retrieval operations
- Consider these tradeoffs when choosing this option for production workflows
- Other models: Depending on your Graphor configuration
2. Elements to Remove
Choose which document element types to exclude from chunking using the multi-select dropdown:- None: Include all document elements (default)
- Or select specific element types to exclude, such as:
- Header: Remove headers at the top of pages
- Footer: Remove footers at the bottom of pages
- Page number: Remove page numbering elements
- Figure caption: Remove image captions
- And other element types as needed
3. Splitter Type
Select your preferred chunking strategy from the available options (Smart chunking, By Character, By Element, By Tokens, By Semantic).4. Chunk Size and Other Parameters
Configure the additional parameters required for your selected strategy:- For Smart Chunking: Set Chunk Size (maximum allowed size; actual chunks will typically be smaller)
- For By Character: Set Chunk Size (maximum), Overlap, and optional Separator
- For By Tokens: Set Chunk Size (maximum) and Overlap
Chunk Size Considerations
The size of your chunks is a critical factor in retrieval quality:Small chunks (1000-2000 characters)
Small chunks (1000-2000 characters)
Advantages:
- More precise retrieval for specific information
- Reduced token usage when processing retrieved chunks
- Better for simple, direct questions
- May lose important context
- Can fragment related concepts
- Might require retrieving multiple chunks to get complete information
Medium chunks (3000-5000 characters)
Medium chunks (3000-5000 characters)
Advantages:
- Good balance between precision and context
- Preserves most semantic relationships
- Works well for most general-purpose applications
- May still split some complex discussions
- Moderate token usage
Large chunks (6000-8000 characters)
Large chunks (6000-8000 characters)
Advantages:
- Maximizes context preservation
- Better for complex, multi-part questions
- Reduces fragmentation of ideas
- May include irrelevant information
- Higher token usage when processing retrieved chunks
- Can reduce precision for simple queries
Recommended Settings by Document Type
Different documents require different chunking approaches:| Document Type | Recommended Strategy | Typical Chunk Size | Notes |
|---|---|---|---|
| Technical documentation | Smart chunking | 3000-5000 | Preserves structure |
| Articles and blogs | Smart chunking | 3000-4000 | Good for narrative flow |
| Legal documents | By Tokens | 4000-6000 | Precise token control |
| Code and technical specs | By Element | N/A | Keeps code blocks intact |
| Structured data | By Element | N/A | Preserves table structures |
| Multi-language content | By Semantic | N/A | Better language boundary handling |
Troubleshooting Common Issues
Missing important information in retrieval
Missing important information in retrieval
Solutions:
- Increase chunk size
- Switch to Smart chunking or By Semantic
- Ensure important element types aren’t being removed
- Verify document parsing quality
Repetitive or duplicate content
Repetitive or duplicate content
Solutions:
- Reduce overlap settings
- Remove headers/footers and page numbers
- Check for duplicate content in your dataset
- Use By Element strategy for structured documents
Contextual relationships lost
Contextual relationships lost
Solutions:
- Switch from By Character to Smart chunking
- Review document classification results
- Increase chunk size to preserve more context
- Use By Semantic for context-heavy documents
Best Practices
- Match strategy to content: Choose your chunking strategy based on document type and structure
- Start with Smart chunking: This works well for most general documents
- Test different approaches: Experiment with strategies and settings using the same queries
- Consider user questions: Align chunking with the types of questions users will ask
- Remove noise: Configure element removal to exclude irrelevant content
- Evaluate and iterate: Use evaluation tools to measure and refine your approach
Next Steps
After optimizing your chunking configuration, explore:Retrieval
Configure search parameters and algorithms of your RAG
Evaluation
Measure and improve your RAG pipeline performance with comprehensive metrics
LLM Integration
Connect language models to utilize your chunked content effectively
Integrate Workflow
Connect your RAG systems to applications via REST API and MCP Server integration