This guide explains the retrieval component in Graphor - the critical process that finds and ranks relevant information based on user queries. You’ll learn about retrieval strategies, configuration options, and best practices to ensure your RAG pipeline delivers the most accurate and relevant information.Documentation Index
Fetch the complete documentation index at: https://docs.graphorlm.com/llms.txt
Use this file to discover all available pages before exploring further.

Overview
Retrieval is the heart of any RAG (Retrieval-Augmented Generation) system. It determines:- How user queries are processed
- Which document chunks are deemed relevant
- How information is ranked by relevance
- What context is provided to the LLM for response generation
The Retrieval Component
In Graphor’s Flow Builder, the Retrieval component connects your indexed documents to the response generation process: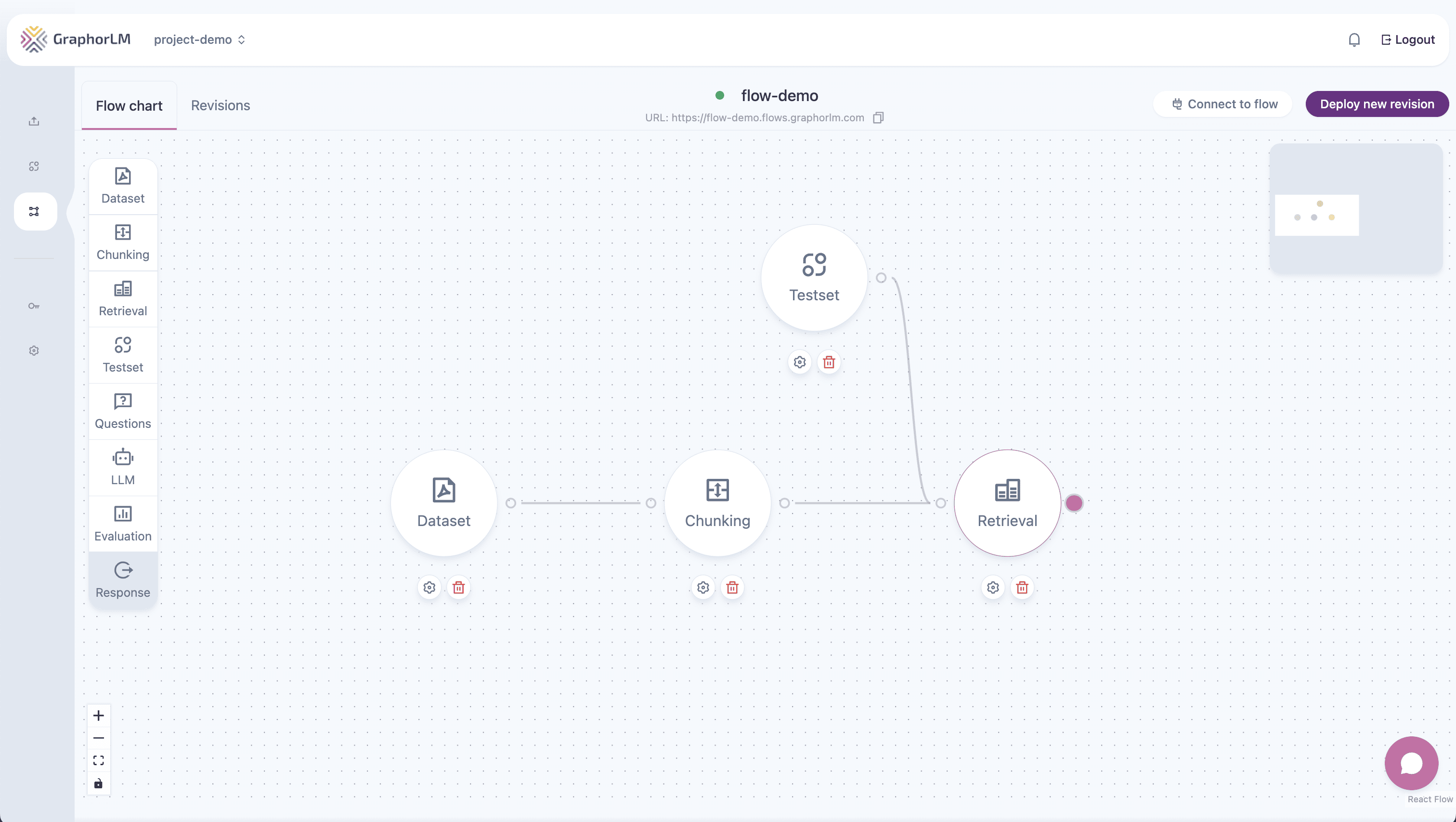
Configuring the Retrieval Component
To set up retrieval for your RAG pipeline:- Add the Retrieval component to your flow
- Connect the output of your Chunking component to the input of the Retrieval component
- Double-click the Retrieval component to open its configuration panel
- Configure the following settings:
Search Type
Graphor offers several search methods for retrieving information:-
Similarity: The most common retrieval method that finds chunks with vector embeddings closest to the query embedding
- Best for general question answering
- Works well for semantic understanding
- Recommended for most use cases
-
Full text: Traditional keyword-based search within document chunks
- Finds exact word or phrase matches
- Good for precise terminology and specific queries
- Less effective for conceptual questions with different wording
-
Hybrid: Combines vector similarity with keyword-based (full text) methods
- Combines benefits of semantic search and keyword matching
- Can be more robust for specialized terminology
- May improve precision for specific domains
Top K
Set the number of chunks to retrieve for each query:- Lower values (1-3): More focused responses, but may miss relevant information
- Medium values (4-8): Balanced approach, recommended for most use cases
- Higher values (9+): More comprehensive information, but may include less relevant content
Score Threshold
Define the minimum relevance score (0.0 to 1.0) for a chunk to be included in the results:- Lower thresholds (0.3-0.5): More inclusive, but may include less relevant information
- Medium thresholds (0.5-0.7): Balanced approach for most use cases
- Higher thresholds (0.7+): More strict filtering, ensuring only highly relevant chunks
Testing Retrieval Performance
Graphor provides powerful tools to test and optimize your retrieval configuration before deploying your RAG pipeline. You can test using individual questions or comprehensive test sets:Using Question Nodes
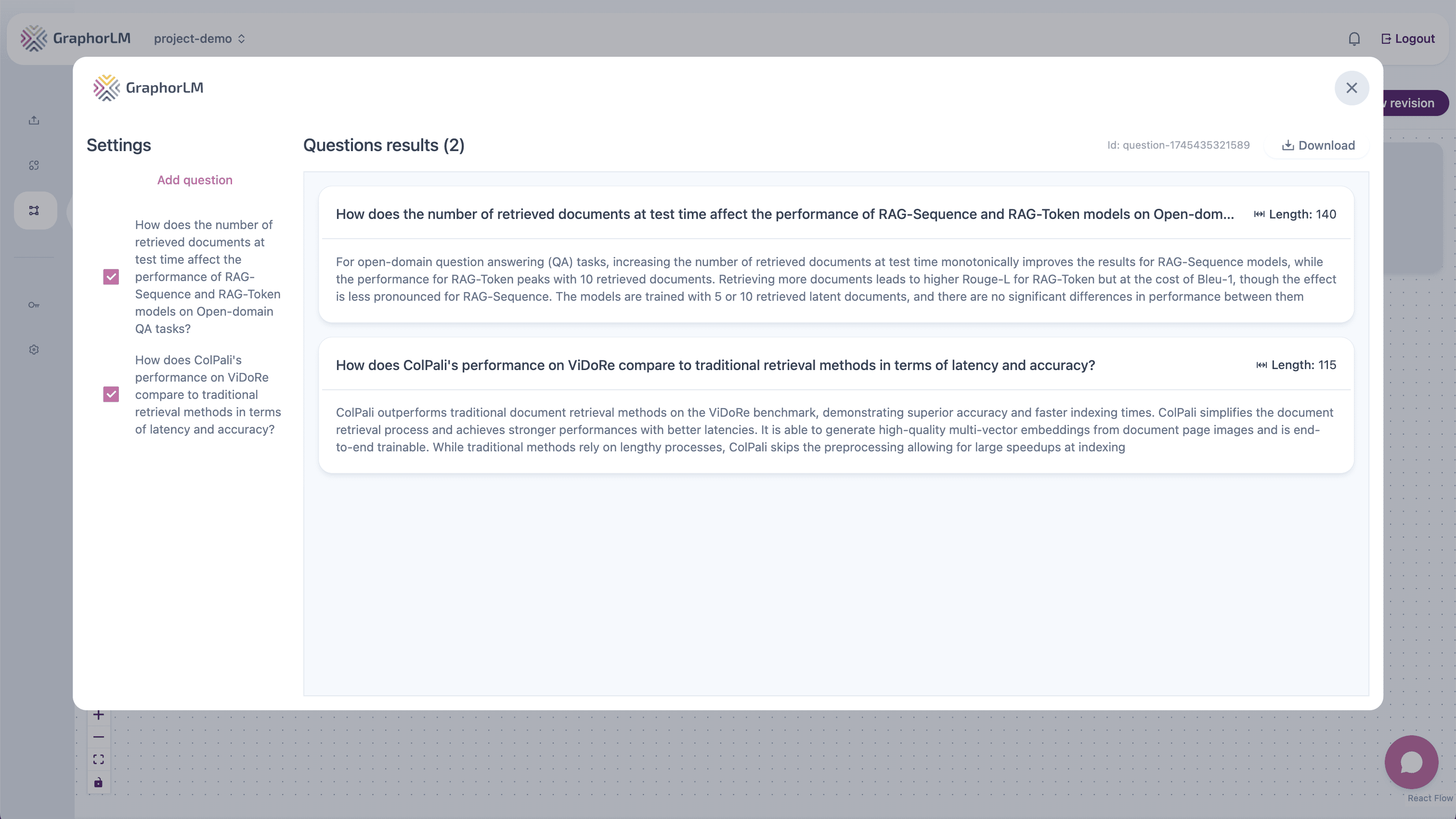
For quick testing with individual queries:- Add a Question node to your flow
- Connect it to the Retrieval component’s input
- Double-click to open the Question node’s configuration panel
- Enter sample questions that represent real user queries
- Click Update Results to see which chunks are retrieved
- Review the retrieved chunks and their relevance scores
- Adjust your retrieval settings and test again to optimize performance
Using Testset Nodes
For systematic testing with multiple queries:-
First, create a testset:
- Navigate to the Testsets section in the left sidebar
- Click New Testset to create a new collection of test questions
- Add multiple questions that represent different query types
- Optionally add expected answers for evaluation
- Save your testset with a descriptive name
-
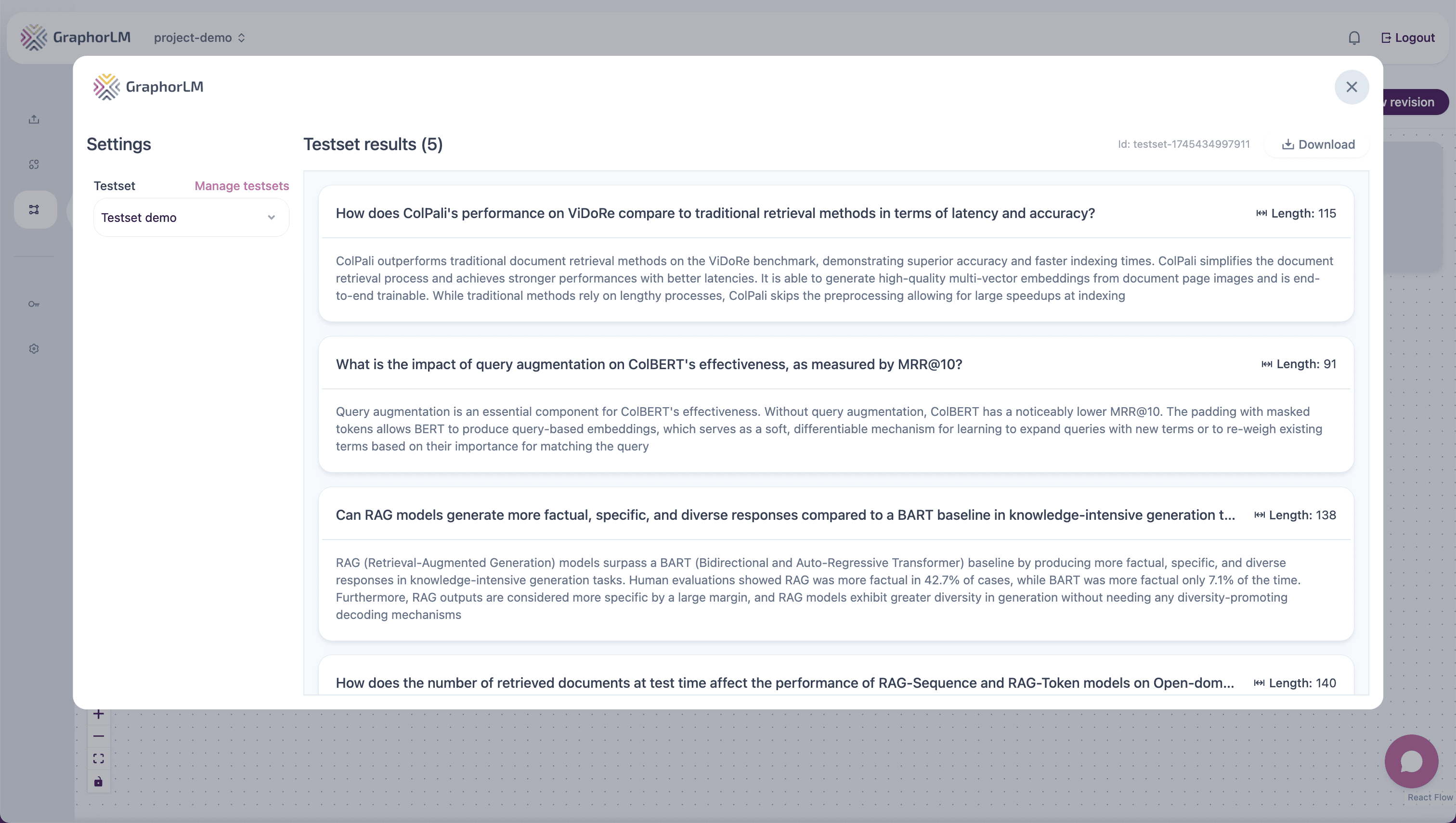
Then use the testset in your flow:
- Add a Testset node to your flow
- Connect it to the Retrieval component’s input
- Double-click to open the Testset node configuration
- Select your previously created testset from the dropdown
- Click Update Results to evaluate retrieval performance across all questions
- Review the results for each question in your testset
- Comprehensive evaluation across diverse query types
- Systematic comparison of different retrieval configurations
- Regression testing when making changes to your RAG pipeline
- Building evaluation datasets for ongoing optimization
Interpreting Test Results
When reviewing retrieval results, pay attention to:- Relevance scores: How confident is the system in each result?
- Content relevance: Do the chunks actually contain information that answers the query?
- Missing information: Are important details absent from the retrieved chunks?
- Irrelevant content: Are chunks being retrieved that don’t relate to the query?
Retrieval Strategies for Different Use Cases
Different applications may benefit from different retrieval configurations:Question Answering
- Recommended setup: Similarity search with Top K = 4-6
- Score threshold: 0.5-0.6
- Focus on: Precision and directly answering the query
Document Exploration
- Recommended setup: Similarity search with Top K = 6-10
- Score threshold: 0.4-0.5
- Focus on: Coverage and diverse information
Technical Support
- Recommended setup: Hybrid search with Top K = 3-5
- Score threshold: 0.6-0.7
- Focus on: Accuracy and retrieving specific instructions
Research Applications
- Recommended setup: Combination of multiple retrieval strategies
- Score threshold: Variable based on query type
- Focus on: Comprehensive information gathering
Troubleshooting Retrieval Issues
Missing relevant information
Missing relevant information
Solutions:
- Increase Top K value
- Lower the score threshold
- Try a different search type
- Check if chunking strategy is appropriate
- Verify the query is well-formed
Too much irrelevant information
Too much irrelevant information
Solutions:
- Decrease Top K value
- Increase the score threshold
- Use Full text search for more precise matching
- Review chunking strategy for better semantic units
Slow retrieval performance
Slow retrieval performance
Solutions:
- Reduce dataset size
- Lower Top K value
- Simplify search type (e.g., use Similarity instead of Hybrid)
- Review embedding model choice
Best Practices
- Start simple: Begin with Similarity search and adjust if needed
- Test with real queries: Use actual questions your users might ask
- Balance Top K: Find the sweet spot between too much and too little context
- Tune score threshold: Adjust based on the specificity of your knowledge base
- Coordinate with chunking: Retrieval performance is heavily influenced by your chunking strategy
- A/B test configurations: Compare different settings with the same queries
- Monitor and adjust: Regularly review how your retrieval is performing with real users
Next Steps
After optimizing your retrieval configuration, explore:Reranking
Add LLM-based reranking for more precise results
LLM Integration
Generate responses using retrieved content
Evaluation
Measure and improve your RAG pipeline performance
Integrate Workflow
Deploy via REST API and MCP Server