Overview
While Graphor focuses primarily on high-quality information retrieval, you can optionally add an LLM component to your pipeline to transform retrieved information into natural language responses. It’s important to note that using an LLM node is completely optional - many users can achieve their goals using just the Retrieval component as the final output.When to Use Retrieval Only
The Retrieval component can serve as the final stage of your RAG pipeline when:- You need direct access to the most relevant document chunks
- You’re integrating with your own custom LLM solution
- You want to implement your own response generation logic
- You’re primarily focused on document search functionality
- You want to optimize resource usage for LLM API calls
When to Add an LLM Component
Consider adding the LLM component when:- You need natural language responses generated from retrieved content
- You want a complete end-to-end solution without additional integration
- Your use case requires synthesizing information across multiple documents
- You need complex reasoning beyond simple retrieval
The LLM Component
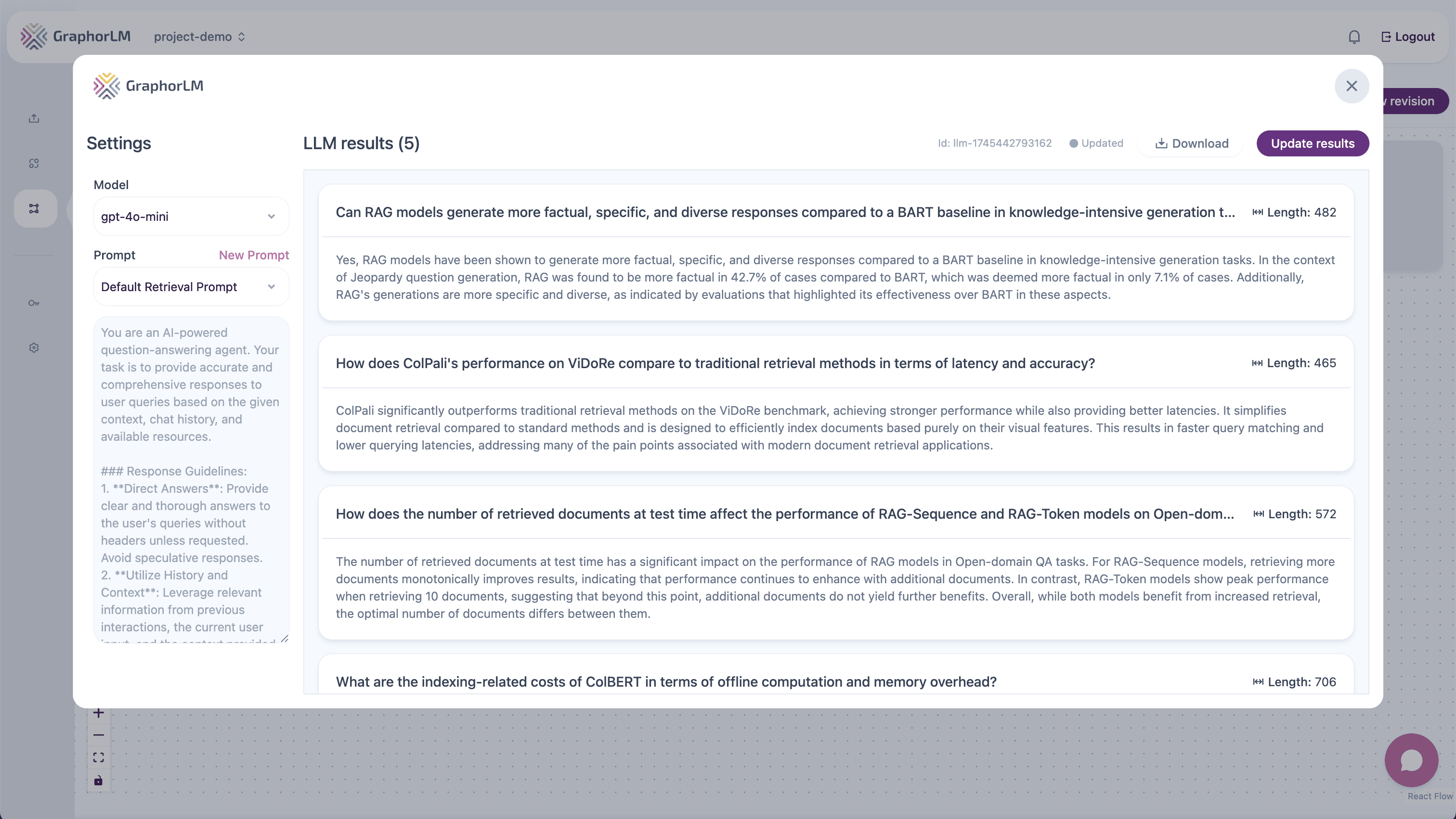
In Graphor’s Flow Builder, the LLM component takes retrieved document chunks as input and uses them to generate natural language responses: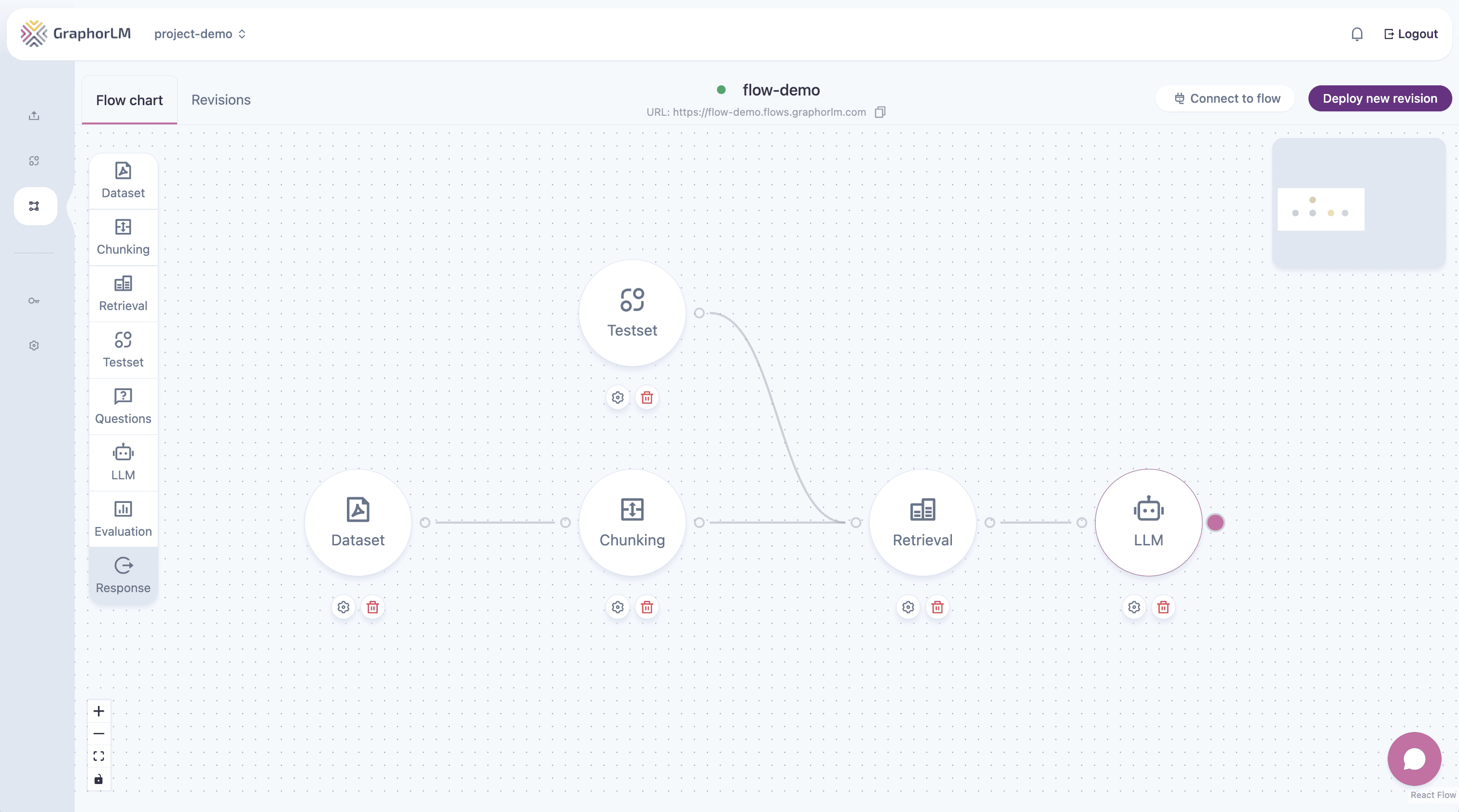
Configuring the LLM Component
To set up the LLM component for your RAG pipeline:- Add the LLM component to your flow
- Connect the output of your Retrieval component to the input of the LLM component
- Double-click the LLM component to open its configuration panel
- Configure the following settings:
Model Selection
Graphor supports integration with various language models:-
OpenAI models:
- GPT-4o
- GPT-4 Mini
-
Local models (when configured):
- Various open-source models depending on your deployment
System Prompt
The system prompt defines the LLM’s behavior and instructions for generating responses. You can customize this prompt to:- Define the assistant’s personality and tone
- Specify formatting requirements
- Provide domain-specific context
- Set boundaries for what the assistant should and shouldn’t do
Prompt Engineering
Effective prompt design is crucial for getting optimal results from the LLM component.Basic Prompt Structure
Graphor automatically structures prompts using this general pattern:- System prompt: Sets the tone and provides general instructions
- Retrieved context: Inserts the information retrieved from your documents
- User query: Adds the user’s actual question
- Response instructions: Provides specific guidance on how to answer
Prompt Engineering Best Practices
- Be specific and clear: Provide detailed instructions about what you want
- Use examples: Include examples of desired responses when possible
- Structure matters: Order your instructions in a logical sequence
- Test and iterate: Refine prompts based on the responses you get
Testing LLM Responses
To test your LLM configuration:- Make sure you have a Question or Testset node connected to your Retrieval nodes
- Configure your LLM component
- Click Update Results to see the generated response
- Review the response for:
- Accuracy and factual correctness
- Adherence to the system prompt
- Proper use of retrieved information
- Overall usefulness and clarity
Next Steps
After exploring LLM integration, you may want to learn more about:Reranking
Add LLM-based reranking before generating responses
Evaluation
Measure and improve your RAG pipeline performance
Integrate Workflow
Deploy via REST API and MCP Server
Retrieval
Optimize retrieval to provide better context